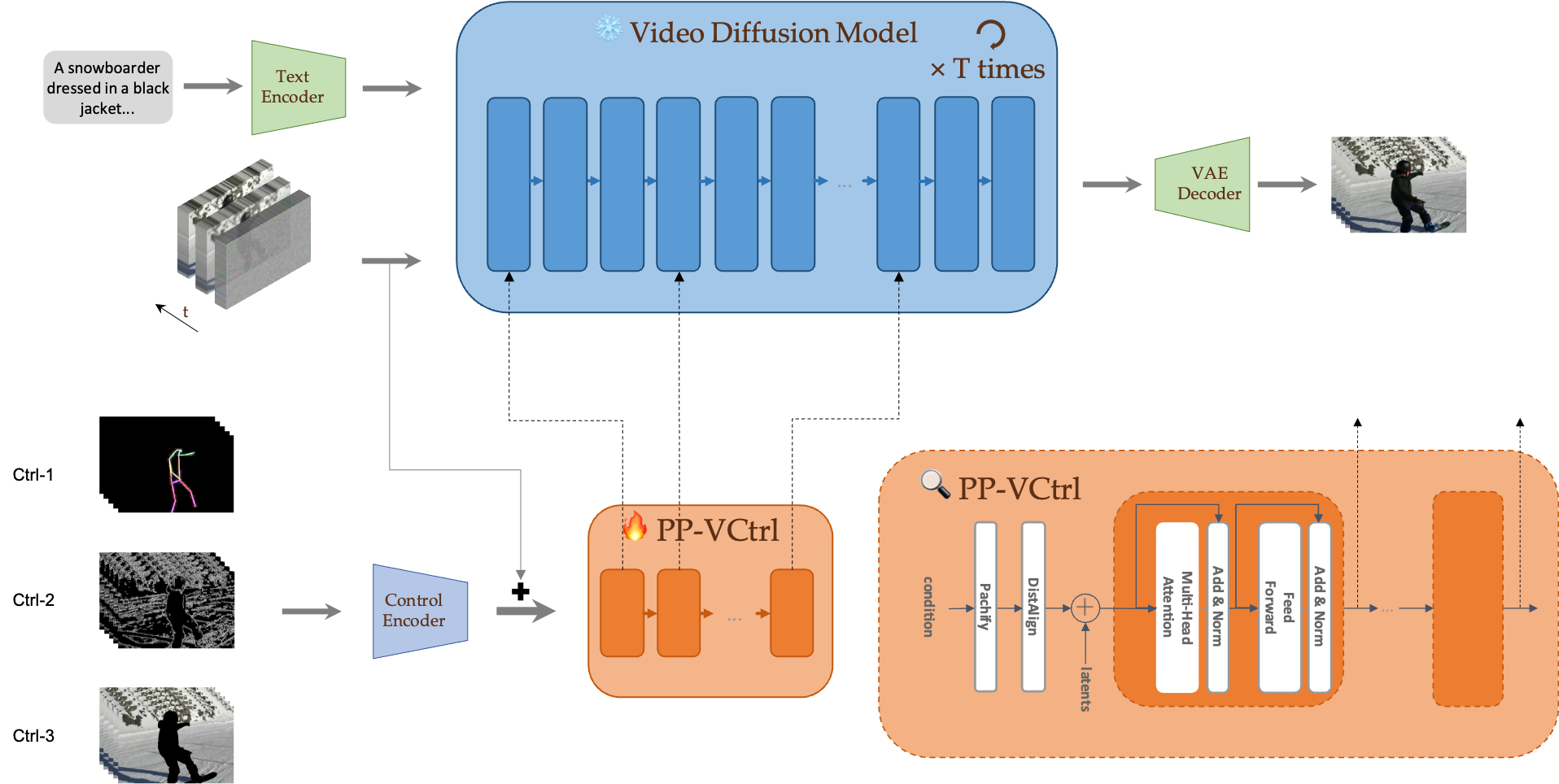
In recent years, text-to-video diffusion models have transformed the landscape of video generation, yet they often struggle with fine-grained control over spatiotemporal dynamics. This paper introduces PP-VCtrl, a novel architecture that enhances existing text-to-video models by integrating a unified conditional encoder, enabling versatile control through auxiliary conditioning signals such as Canny edges, human poses, and segmentation masks. Our approach maintains the integrity of the original generator while allowing for efficient incorporation of diverse control inputs. We demonstrate that PP-VCtrl achieves enhanced performance across various video generation tasks, significantly improving control fidelity and visual quality compared to previous methods. Comprehensive experiments validate the effectiveness of our framework, showcasing its potential for practical applications in controllable video generation.